
CRISP-DMとは、データ分析プロセスのフレームワーク
CRISP-DMとは、データ分析を効率よく行うためのフレームワークです。CRISP-DMは、6つのステップに分かれており、下記のような図で表されます。
図を見て分かるように、データ分析のプロセスは一方通行的なものではなく、複数のプロセスを行ったり戻ったりしながら進んでいきます。
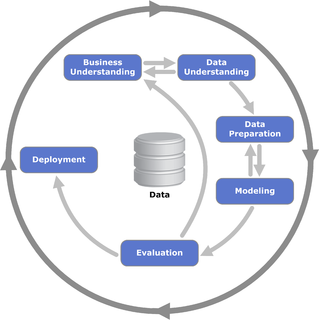
(引用:「Cross-industry standard process for data mining」)
CRISP-DMの6ステップ
Business Understanding(ビジネス理解)
データ分析を行う前にまず必要なのは、しっかりとビジネス理解をすることです。闇雲にデータを触るのではなく、まず現状の課題、ボトルネック、仮説を洗い出し、それぞれの関係をまとめましょう。
そうすることで、「どのようなデータが必要なのか?」「どれくらい必要なのか?」「KPIや検証方法はどうするか?」などを明確にすることが可能です。
Data Understanding(データ理解)
ビジネス理解と並行して行っていくプロセスが「データの理解」です。
「どんなデータがどれくらいあるのか?」といったデータの質と量、欠損値や外れ値の把握をしていきます。このプロセスでは、EDA(探索的データ分析)という手法が用いられるケースが多いです。
Data Preparation(データの前処理)
このプロセスでは、モデリングの際にデータが利用できる形にします。いわゆる「前処理」と呼ばれるものです。データの前処理では、主に以下のような処理をします。
・データの集約
・外れ値や欠損値の処理
・カテゴリ変数のエンコーディング
・数値の正規化
・特徴量エンジニアリング
この工程は地道な作業が多く時間も手間もかかりますが、データ分析を行う上で非常に重要な工程です。
Modeling(モデル構築)
データの前処理が終わったら、ようやくモデル構築です。「データ分析」と聞くと、このモデル構築の工程を連想する方も多いことでしょう。
さまざまなライブラリが存在しているため、モデリング自体はさほど難しい工程なしで行うことができます。また、多くの学習モデルの中から、分析の対象やビジネス課題に合ったものを選択する必要があります。
例えば「解釈の容易性 or 精度のどちらを優先するのか?」「分類なのか回帰なのか?」「画像データなのか時系列データなのか、その他なのか?」などを考慮して、最適なモデルを選択しましょう。
Evaluation(モデルの評価)
モデルの構築が完了したら、次にそのモデルが、最初に立てたビジネス課題を解決するに足るモデルなのかを評価します。もし、どれだけそれらしいモデルができたとしても、実際のビジネスに活用できない場合、最初のプロセスである「ビジネス理解」に戻る必要性もあります。
Deployment(施策実行)
ビジネスに活用できるモデル構築ができたら、実際の業務フローに落とし込んでいきます。一回作ってモデルは「作ったら終わり」ではなく、継続して活用可能なモデルとなるよう、定期的にデータの更新や再構築が必要となります。



